May 2, 2014 4
GTFS Visualizations
GTFS is an abbreviation for General Transit Feed Specification, a standard which “defines a common format for public transportation schedules and associated geographic information”. Basically this is a possibility for public transport agencies — like the Stadtwerke Ulm/Neu-Ulm (SWU) for example — to release their data to the public in a proper manner. Fortunately some agencies have done so (here’s a list). In Germany the agencies in Ulm and Berlin have released their schedule data under a free license as GTFS. In both cases this process was pushed forward by local Open Data enthusiasts who were involved in this process. Together with some friends from the UlmAPI group, I was involved within the efforts here in Ulm and it has since tempted me to create something from this data.
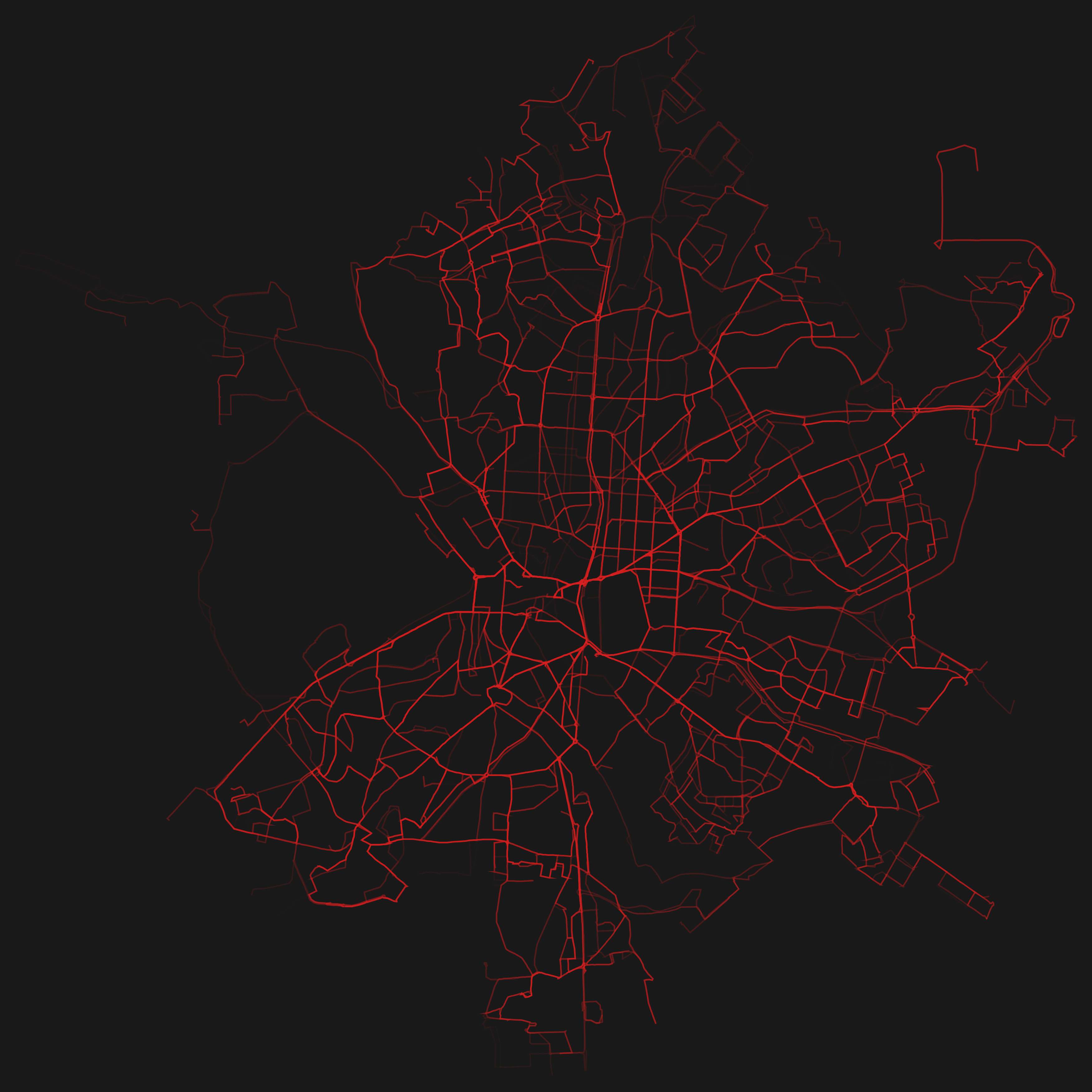
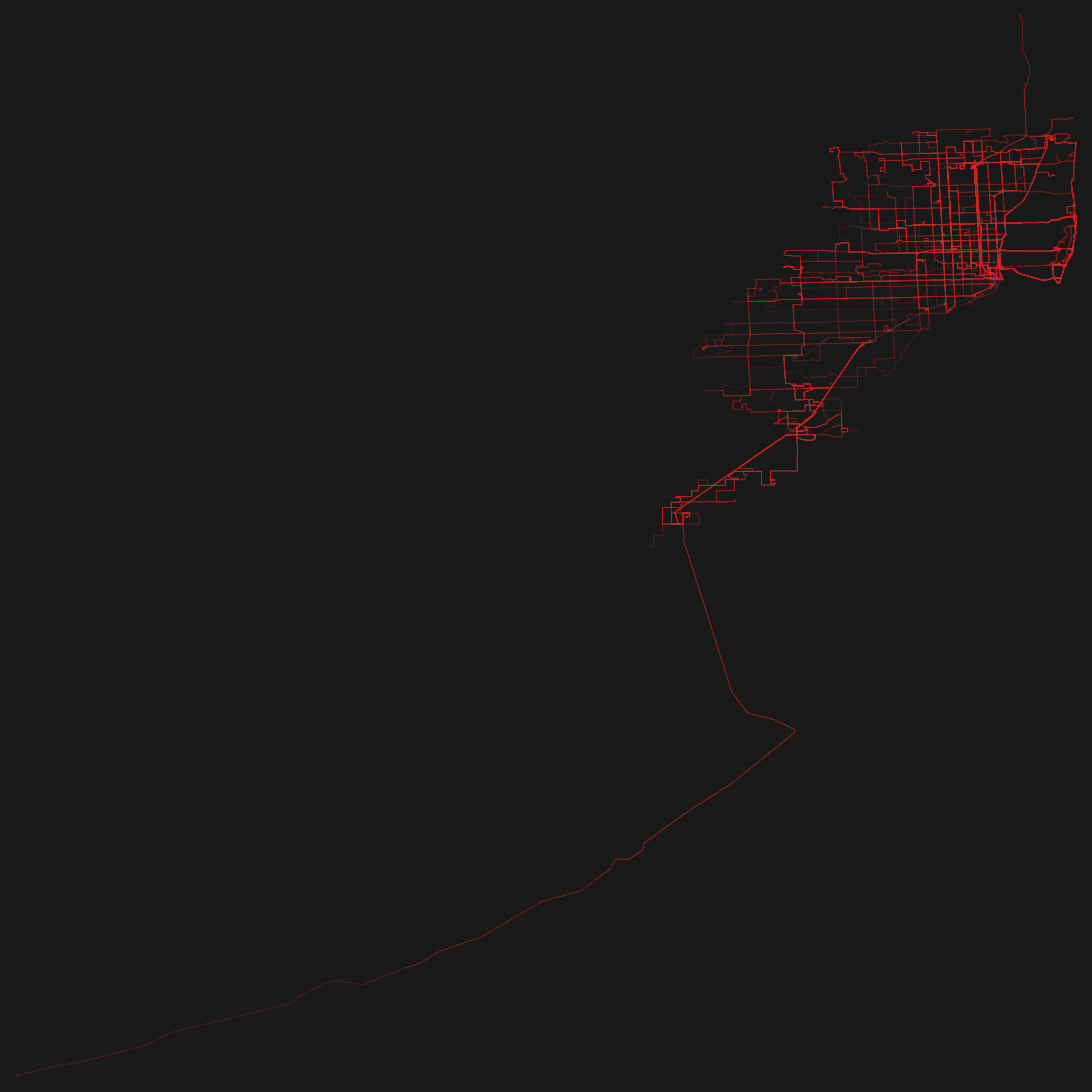
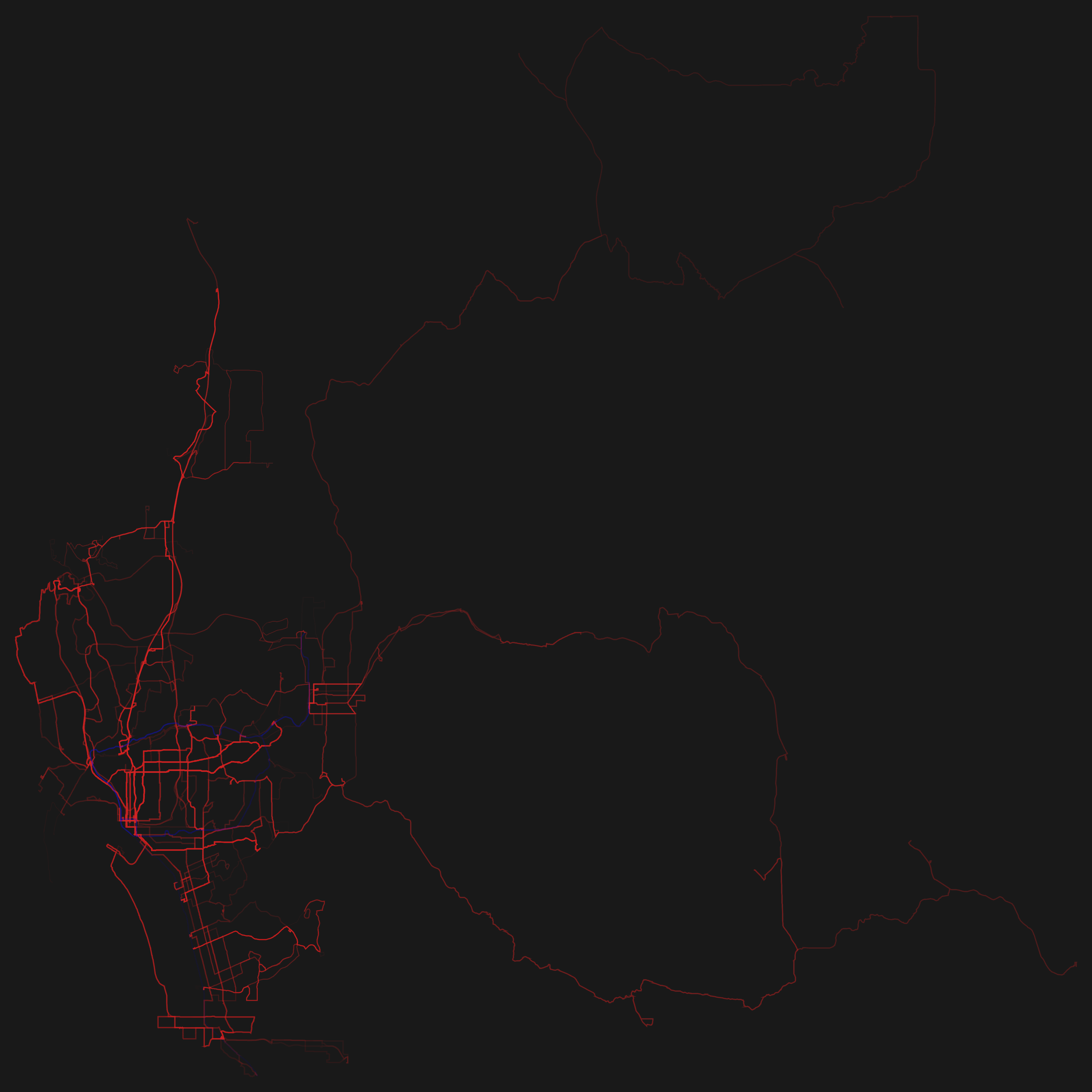
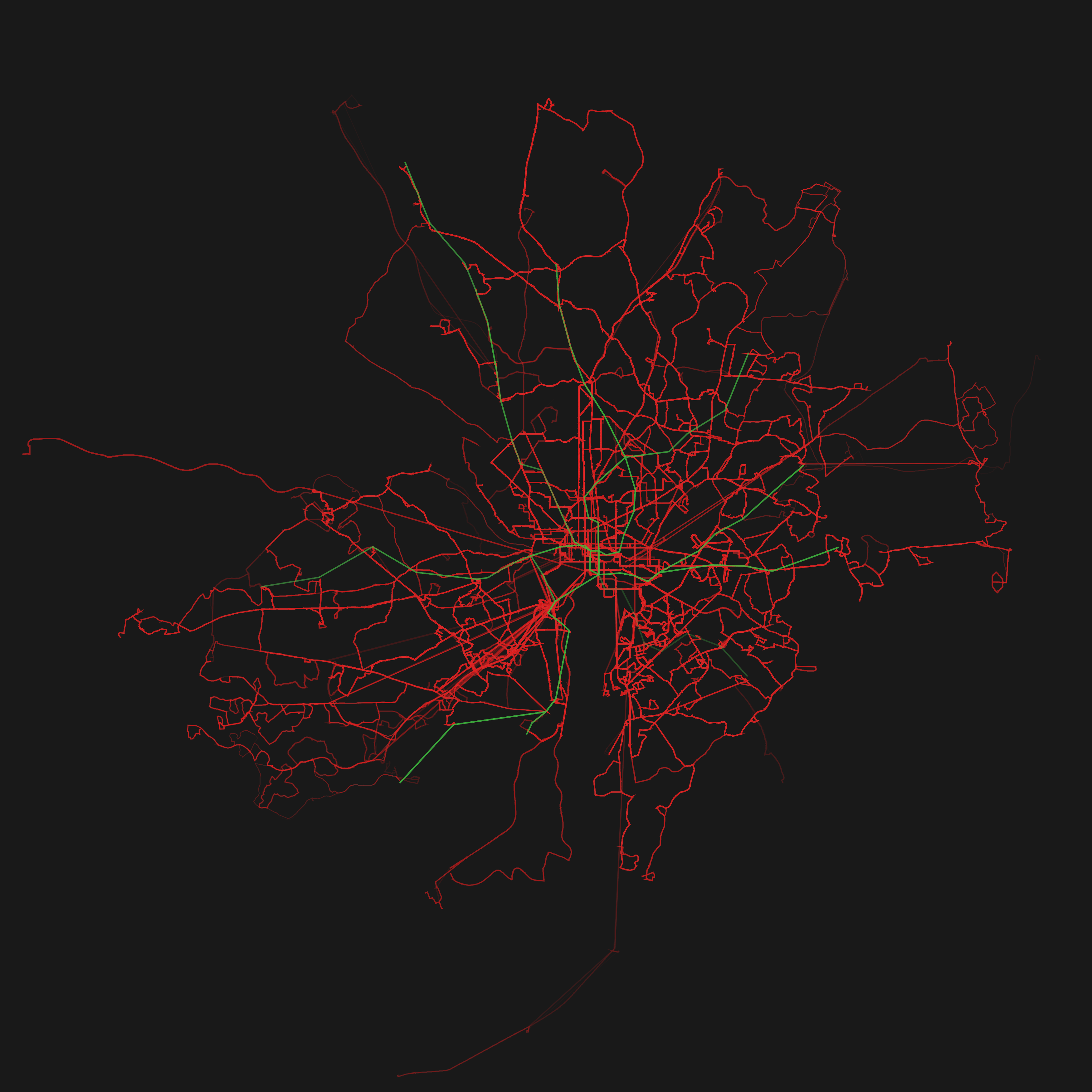
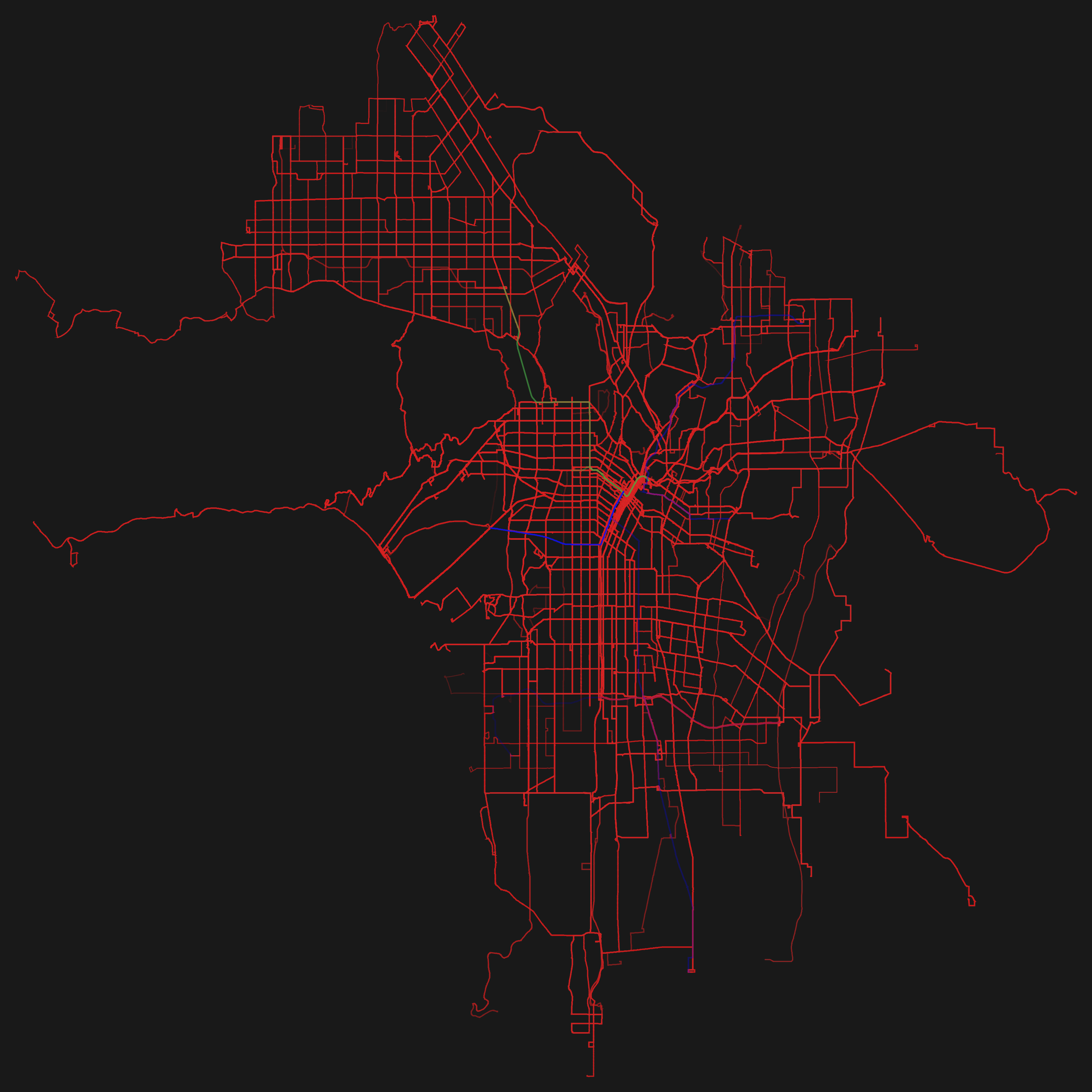
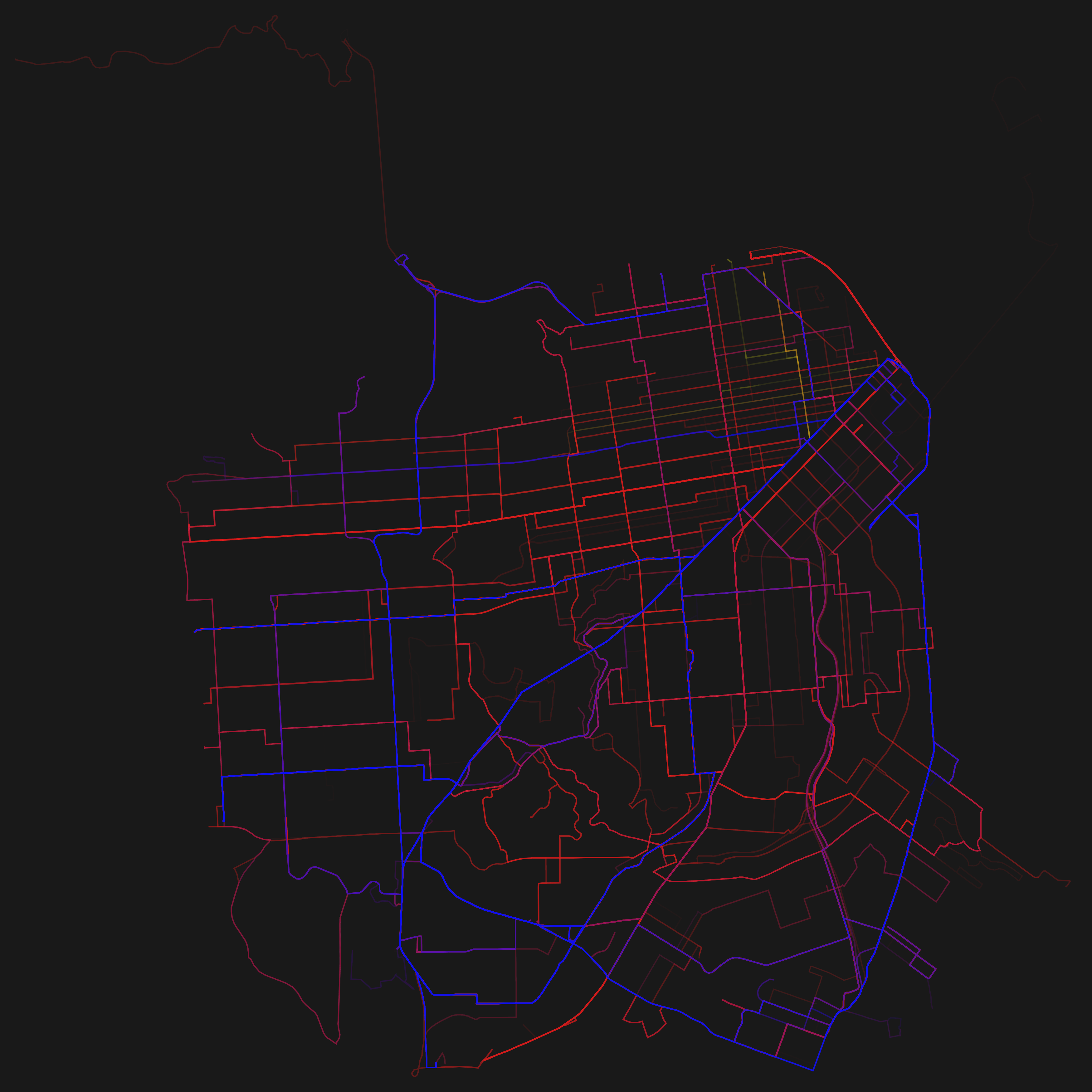
So basically I wrote a program which visualizes GTFS. The program draws the routes which transportation entities take and emphasizes the ones which are frequented more often by painting them thicker and in a stronger opacity. Since many agencies have released their schedule as GTFS it is easily possible to reuse the program as a mean to visualize different transportation systems in different cities.
So here are the renderings for some GTFS feeds! Just click on the thumbnails to get a larger image. The color coding is: red=busses, green=subway/metro, blue=tram.







I am very satisfied with the resulting images, which in my opinion look really beautiful. I have rendered some of the cities as PDFs as well. With the momentary program, this is a very time consuming process and for some cities — due to performance or memory issues — not even possible on my (quite sophisticated) pc. This is due to the enormous transportation schedule (> 300 MB, ASCII) of some cities. But my program can surely be heavily optimized.
Please note: These visualizations would not exist without Open Data. This project was only possible because of transport agencies releasing their data under a free license. One should not forget that the existence of projects like this is a major benefit of Open Data.
Also one should not forget that standardized formats in the Open Data scene have proven to be a major benefit. Existing applications can easily be re-deployed like in the case of Mapnificent, OpenSpending or, well, in mine.
The best thing to do with your data will be thought of by someone else.
License & Code
The images are licensed under a Creative Commons Attribution 4.0 International license (CC-BY 4.0). Feel free to print, remix and use them! The source code is available via GitHub under the MIT license. Please note that it definitely has to be properly refactored since it wasn’t designed, but rather grew. That’s also the reason for using two different technologies (node.js and processing) within the project. I had a different thing in mind when I started coding.
Preventing misunderstandings
To prevent misunderstandings: The visualizations show only the data released by the according agencies! So in the case of e.g. Madrid there exists a metro line which is not shown in the visualization above. This is due to a different agency — who has not yet released their data as GTFS — operating the metro line. I hope that more agencies start to make their data freely available after seeing which unexpected and beautiful results they might get.
Another misunderstanding which I want to directly address: The exact GTFS feed is visualized. This means that when looking closely at the resulting PDF you may find some lines which are very close to another and might even overlap in part. This is no bug, but the way the shapes are defined in the feed.
Printing
If you want to print the visualizations: I have created two posters (DIN A0). The graphics within them are properly generated PDFs in CMYK. So be aware that the colors will look different on your screen than when printed.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}